A Design Problem
The following example of a “Marimekko“ graph (also referred to as a “Mekko,” “mosaic,” or “matrix” graph) was brought to my attention by students in the MBA course that I teach at the University of California, Berkeley. I believe that the image originally came from www.mekkographics.com.
[Scroll down to see our solution to this graph's design problems.]
My Analysis
This graph encodes two quantitative variables: one using the height and one using the width of the bars. By attending to the heights of each bar segment, we can see what percentage of each company’s total sales were handled by each of the three sales channels. By attending to the widths of the bars, we can see the relative magnitudes of each company’s total sales. Each company’s sales in each individual channel is encoded through the areas of the rectangles (that is, the individual bar segments). For instance, comparisons between Reebok’s U.S. sales and Adidas’ International sales can be made by comparing the areas of the two rectangles that represent them.
Marimekko charts function similarly to treemaps, a tool for hierarchical data analysis that was invented by Ben Shneiderman. If you are unfamiliar with treemaps, Ben wrote an informative article about them, which I featured in 2006. Both Marimekko charts and traditional treemaps segment a rectangular area into smaller rectangles. In both cases, the areas of the rectangles encode data. In the case of treemaps, an additional quantitative variable is encoded through color. Although the length and width of the different rectangles in a treemap might vary, no values are encoded by either of these dimensions individually. Area is the only spatial dimension used to encode data in treemaps. In the case of Marimekko charts, however, separate values are encoded by the length and the width of each rectangle. As such, all of the variables in a Marimekko graph are spatially encoded. We can easily view some pairs of visual attributes independently, but others we can only easily view together as a whole. For instance, we can easily see the area and the color of objects independently. These are called “separable” visual dimensions. It is easy, for example, to quickly find all of the large rectangles, all of the blue rectangles, or all of the large blue rectangles in a display that consists of red and blue rectangles of varying sizes. Other pairs of attributes are called “integral” visual dimensions. In this case, we tend to perceive the dimensions holistically, not independently. For instance, the lengths and widths of rectangles are perceived holistically as their areas. If we try to find all of the tall rectangles in a display, our eyes will be drawn to the tall rectangles with the largest area, even though there might be other rectangles of similar heights that we have trouble noticing because they have small widths. In order to search for differences in only width or only height, we are required to work harder and spend more time than we would if focusing on the differences of two separable visual dimensions. This problem might not seem significant in the case of the graph above, but as the amount of data increases, it becomes more and more of a problem. Some treemaps successfully encode more than 1 Million items across two variables. A Marimekko graph with 1/1000th of that amount of data would only support comparisons of the areas; overall comparisons of height and width would be difficult.
This leads us to the next problem with Marimekko graphs. After we’ve viewed the graph as a whole, we’ll probably want to make individual comparisons between specific boxes. However, accurate comparisons of area are not something that people can do well. For instance, is it obvious whether Reebok or Adidas has more International Sales in dollars? Can you tell whether Adidas or Fila has more U.S. Sales? These dollar values are represented by the Marimekko chart, but they are encoded in the area of the boxes—an attribute which we have difficulty comparing—so this information cannot be accurately perceived.
Additionally, Marimekko graphs suffer from a problem that plagues any stacked bar graph: It is difficult to accurately make comparisons of the width or height of boxes that are not arranged next to one another along a common baseline. As such, because the bar segments that represent International Sales do not share a common baseline, it is harder than necessary to compare their heights. For instance, does Nike or Reebok have a higher percentage of International Sales? They’re definitely close, but without a common baseline we cannot definitively tell whether one is larger or they’re the same. This problem is magnified when trying to compare bar segments within the same column, because they are stacked on top on one another rather than arranged side by side. For instance, it is difficult to accurately compare Reebok’s U.S. and International Sales or Converse’s International and Licensed Sales.
The Marimekko graph encodes the following information:
- sales per company
- sales per channel
- sales per company and channel
Unfortunately, each set of values is encoded in a way that is difficult to decode and compare (areas of bars, heights of bars stacked on top of one another, and widths of bars along an uneven baseline).
A Solution
My redesign is simple. I’ve taken the three sets of values in the Marimekko graph and displayed them in a way that relies on our perceptual strengths, instead of our perceptual weaknesses.
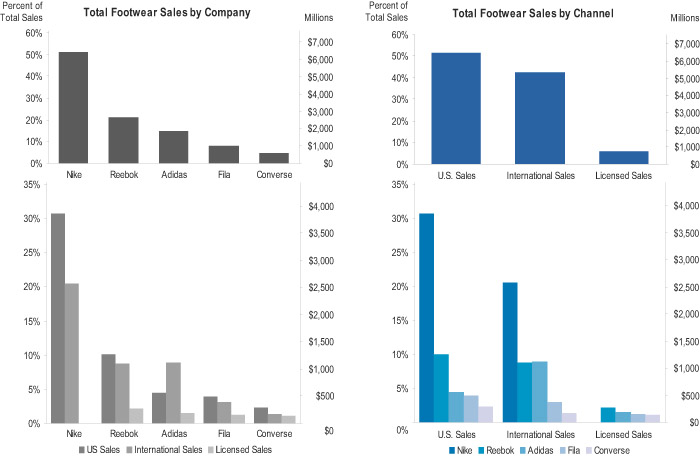
Now certain features jump out immediately that would have required work to see in the Marimekko graph. For instance, we can quickly see that Reebok has more U.S. Sales than International, a difference that was not readily apparent in the original. Additionally, it is now easy to make comparisons between different companies’ sales channels. We can clearly see that Adidas has slightly more U.S. Sales than Fila. Now it’s obvious just how close Reebok is to Adidas in International Sales.
Although all of these graphs can be made from the one Marimekko graph, in most cases they would not all be necessary. Each one features a different aspect of the data, making it easy to view the data from that perspective. You would only need to create those that feature what is important to your intended audience. For instance, the two bottom graphs show the values, grouped in two different ways. The graph on the bottom-left supports easy comparisons between channels for a particular company while the graph on the bottom-right supports easy comparisons between companies for each channel. If one of these comparisons was significantly more important than the other, then both graphs would probably not be necessary.